1. BaseLine简介
早期的后门攻击是通过在训练集图片上植入后门触发器,并修改图片的原始标签为目标标签来实现的,在训练过程中,模型将后门触发器的特征与目标标签进行关联。这种方法难以绕过人工检查,因为人工很容易发现修改过的标签与图片内容不匹配。因此有了针对干净标签攻击 (clean-label attacks) 的研究。现有的干净标签攻击都需要访问所有训练数据以获取知识,但在实际情况中,获取全部分类的训练数据成本高、难实现。例如,训练人脸识别器时,训练集由不同用户上传,攻击者只能修改自己的数据,无法修改其他用户的数据。这会导致干净标签攻击的有效性受到限制,引发了对其实际威胁能力的质疑。
本文基于目标类别的代表性示例的知识,设计了一种实现干净标签后门攻击的算法,对其威胁能力予以肯定。通过插入恶意制作的示例,这些示例仅占目标类别数据大小的0.5%和训练集大小的0.05%,攻击者可以操纵在含有后门触发器示例的污染数据集上训练的模型,使其在测试示例中将任意类别的示例判别为目标类别;训练好的模型在不含有触发器的典型测试示例中仍具有良好的准确性,与模型在干净数据集上的训练效果相似。这种攻击方法在各种数据集和模型上都非常有效,即使触发器被注入到现实场景中。
本文探索了各种防御方法后发现:在原始形式下,此种攻击方法可以逃避最先进的防御措施;经过简单调整后,可以适应下游的防御措施。这种攻击方法的有效性就在于,攻击所生成的触发器具有与目标类别的原始语义相关的特征,难以被模型识别和清除,任何试图去除此类触发器的尝试都会首先损害模型识别目标类别的能力,从而降低模型的准确率。
模型特点:
- Clean label backdoor attacks
- Low poison rate (can be less than 0.05%)
- All-to-one attack
- Only require target class data Dt
- Physical world attacks
- Work with the case that models are trained from scratch
Tiny-ImageNet数据集(该数据集很大,需科学上网下载)
[Code] [Paper]
2. 代码结构
2.1. 目录结构
Text1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| .
├── checkpoint
│ └── resnet18_trigger.npy
├── models # 模型文件夹
│ ├── densenet.py
│ ├── dla.py
│ ├── dla_simple.py
│ ├── dpn.py
│ ├── efficientnet.py
│ ├── googlenet.py
│ ├── __init__.py
│ ├── lenet.py
│ ├── mobilenet.py
│ ├── mobilenetv2.py
│ ├── pnasnet.py
│ ├── preact_resnet.py
│ ├── regnet.py
│ ├── resnet.py
│ ├── resnext.py
│ ├── senet.py
│ ├── shufflenet.py
│ ├── shufflenetv2.py
│ └── vgg.py
├── narcissus_function.py # 触发器生成函数
├── Narcissus.ipynb # Narcissus攻击实例
└── util.py # 一些工具函数
|
2.2. 代码模块说明
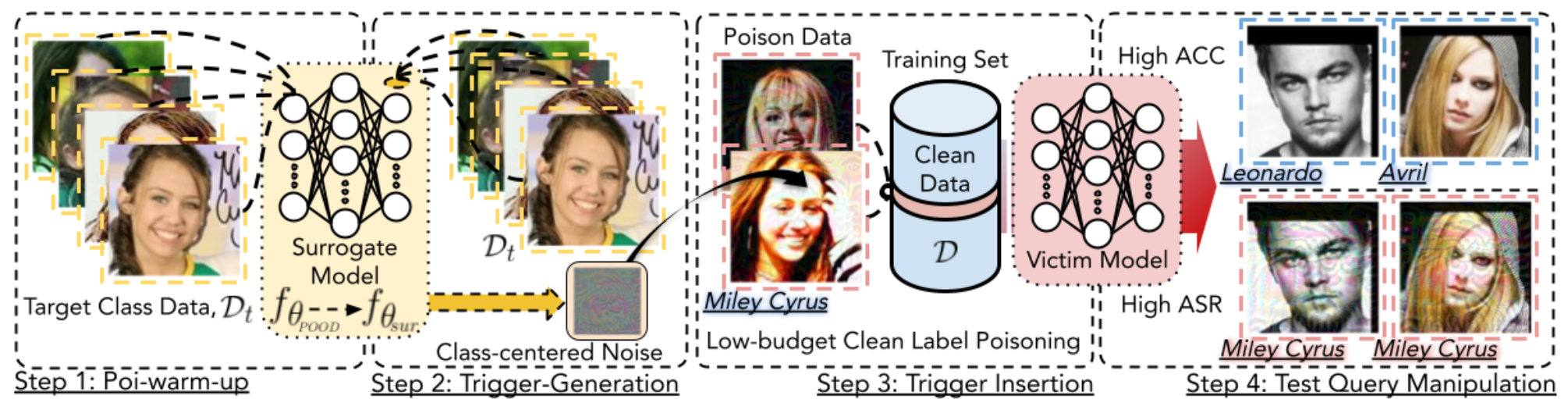
2.2.1. Narcissus.ipynb
- dataset_path:目标数据集和公开的 out-of-distribution (POOD) 数据集的路径。在这里,CIFAR-10 作为目标数据集,Tiny-ImageNet 作为 POOD 数据集。
- lab:目标类别标签。
- noise_size:噪声大小,默认为全图像大小。
- l_inf_r:L-inf 球的半径。
- surrogate_model 和 generating_model:用于生成代理模型和触发器的模型,这里使用的是 ResNet18_201 模型。
- surrogate_epochs:代理模型训练的周期数。
- generating_lr_warmup:毒物预热的学习率。
- warmup_round:预热轮数。
- generating_lr_tri:触发生成的学习率。
- gen_round:生成轮数。
- train_batch_size:训练批次大小。
- patch_mode:添加噪声的模式,这里是 ‘add’,表示将噪声添加到图像上。
训练 surround 模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
condition = True
noise = torch.zeros((1, 3, noise_size, noise_size), device=device)
surrogate_model = surrogate_model
criterion = torch.nn.CrossEntropyLoss()
surrogate_opt = torch.optim.SGD(params=surrogate_model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
surrogate_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(surrogate_opt, T_max=surrogate_epochs)
print('Training the surrogate model')
for epoch in range(0, surrogate_epochs):
surrogate_model.train()
loss_list = []
for images, labels in surrogate_loader:
images, labels = images.cuda(), labels.cuda()
surrogate_opt.zero_grad()
outputs = surrogate_model(images)
loss = criterion(outputs, labels)
loss.backward()
loss_list.append(float(loss.data))
surrogate_opt.step()
surrogate_scheduler.step()
ave_loss = np.average(np.array(loss_list))
print('Epoch:%d, Loss: %.03f' % (epoch, ave_loss))
save_path = './checkpoint/surrogate_pretrain_' + str(surrogate_epochs) +'.pth'
torch.save(surrogate_model.state_dict(),save_path)
|
Poison Warm up 阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
poi_warm_up_model = generating_model
poi_warm_up_model.load_state_dict(surrogate_model.state_dict())
poi_warm_up_opt = torch.optim.RAdam(params=poi_warm_up_model.parameters(), lr=generating_lr_warmup)
poi_warm_up_model.train()
for param in poi_warm_up_model.parameters():
param.requires_grad = True
for epoch in range(0, warmup_round):
poi_warm_up_model.train()
loss_list = []
for images, labels in poi_warm_up_loader:
images, labels = images.cuda(), labels.cuda()
poi_warm_up_model.zero_grad()
poi_warm_up_opt.zero_grad()
outputs = poi_warm_up_model(images)
loss = criterion(outputs, labels)
loss.backward(retain_graph = True)
loss_list.append(float(loss.data))
poi_warm_up_opt.step()
ave_loss = np.average(np.array(loss_list))
print('Epoch:%d, Loss: %e' % (epoch, ave_loss))
|
触发器生成阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
for param in poi_warm_up_model.parameters():
param.requires_grad = False
batch_pert = torch.autograd.Variable(noise.cuda(), requires_grad=True)
batch_opt = torch.optim.RAdam(params=[batch_pert],lr=generating_lr_tri)
for minmin in tqdm.notebook.tqdm(range(gen_round)):
loss_list = []
for images, labels in trigger_gen_loaders:
images, labels = images.cuda(), labels.cuda()
new_images = torch.clone(images)
clamp_batch_pert = torch.clamp(batch_pert,-l_inf_r*2,l_inf_r*2)
new_images = torch.clamp(apply_noise_patch(clamp_batch_pert,new_images.clone(),mode=patch_mode),-1,1)
per_logits = poi_warm_up_model.forward(new_images)
loss = criterion(per_logits, labels)
loss_regu = torch.mean(loss)
batch_opt.zero_grad()
loss_list.append(float(loss_regu.data))
loss_regu.backward(retain_graph = True)
batch_opt.step()
ave_loss = np.average(np.array(loss_list))
ave_grad = np.sum(abs(batch_pert.grad).detach().cpu().numpy())
print('Gradient:',ave_grad,'Loss:', ave_loss)
if ave_grad == 0:
break
noise = torch.clamp(batch_pert,-l_inf_r*2,l_inf_r*2)
best_noise = noise.clone().detach().cpu()
plt.imshow(np.transpose(noise[0].detach().cpu(),(1,2,0)))
plt.show()
print('Noise max val:',noise.max())
|
2.2.2. narcissus_function.py
narcissus_gen()函数生成Narcissus触发器,返回 [1, 3, 32, 32] NumPy数组
def narcissus_gen(dataset_path, lab)
- dataset_path:数据集路径
- lab:目标标签
3. 实验设置
3.1. 数据集
CIFAR-10:目标数据集
Tiny ImageNet:POOD数据集
3.2. 模型选择
ResNet-18
3.3. 训练参数
- lab = 2
- noise_size = 32 (缺省值为全图像大小)
- l_inf_r = 16/255
- surrogate_epochs = 200
- generating_lr_warmup = 0.1
- warmup_round = 5
- generating_lr_tri = 0.01
- gen_round = 1000
- train_batch_size = 350
- patch_mode = ‘add’
对于数据集 CIFAR-10 而言,优化算法选取 SGD,poison ratio为 0.05%,数据增强方式为 Crop 和 H-Flip。
4. 实验结果
4.1. 论文结果
本文的评估侧重于以下三个方面:
- 攻击方法有效性比较;
- 攻击设计选择点的影响;
- 现有防御对本文攻击方法的有效性。
4.1.1. 攻击方法有效性比较
① 攻击效果比较
下表展示的是 CIFAR-10,PubFig 和 Tiny-ImageNet 三个数据集上的超参数和设置,用于测试不同攻击方法的攻击效果。

多种攻击方法在三个数据集上的攻击效果(ACC,Tar-ACC 和 ASR)如下表所示,表中使用红色标注了最高 ASR 的攻击方法。

② 目标类投毒率比较
数据集选取 CIFAR-10 的前提下,不同攻击方法在设置不同目标类投毒率时的攻击效果(Tar-ACC 和 ASR)如下图所示。

4.1.2. 攻击设计选择点的影响
① 代理模型架构(Surrogate model architecture)选择
下表展示的是分别采用 9 个 Surrogate-target 模型对时的 ASR 结果,红色越深,代表可迁移性越强。

② l∞球半径的扰动预算

③ Poi-warm-up 中迭代次数与触发器合成中迭代次数之间的相互作用
下表展示了噪声生成过程中综合不同的 poi-warm-up 迭代次数及不同的触发器合成迭代次数所产生的效果,红色标注的为最佳 ASR 值。

4.1.3. 现有防御对 Narcissus 的有效性
① 给定中毒模型的情况下取消潜在的后门(eg:I-BAU)
下图展示的是使用 CIFAR-10 数据集时 Narcissus 攻击方法在 I-BAU 防御下的效果。下图共包含两个不同的优化器,即 SGD (a) 和 Adam (b),本文将两个优化器微调到最佳学习率, 即 SGD (0.001) 和 Adam (0.0001),并启动 100 轮防御,结果表明,I-BAU 对 Narcissus 性能不稳定。

② 模型不可知的后门检测(eg:基于频率的后门检测器)
下表展示了基于频率的后门样本检测器的检测结果,包含原始 Narcissus 触发器和自适应 Narcissus 触发器的检测结果,其中 Δ 设置为低通滤波器。本文将结果与 Smooth 触发器进行比较。

本文将改编的 Narcissus 与最先进的频率隐形攻击方法进行比较,给出如下图所示的可视化结果,这两种攻击都采用与约束相同的低通滤波器。

下表展示的是不同频率不可见触发器在 CIFAR-10 上的攻击效果,投毒率为 0.8%,Smooth-c 表示干净标签中毒,Smooth-d 表示脏标签中毒,红色标注了最佳 ASR 值。结果表明了 Narcissus 的有效性和适应性。

③ 中毒数据集的鲁棒训练(eg:ABL)
数据集选取 CIFAR-10,使用 ABL 在具有不同投毒率的 Narcissus 攻击方法中训练 WideResNet-16-1 模型的结果如下表所示。“Early”是早期学习后的结果,“Later”结果显示了使用隔离数据取消学习后的性能,也是 ABL 的最终结果,红色标注了失败的防御。

4.2. 实验结果
4.2.1. 训练代理模型 & Poison-warm-up
- 代理模型共训练 200 轮,loss 最终收敛至 0.014:

- Poison-warm-up 过程中的 loss 变化如下:

4.2.2. 生成触发器
模型训练生成的触发器样式和最大噪声值如下图所示。

4.2.3. 测试攻击效果
测试效果如下图所示,运行 200 轮后,ACC 与 ASR 均大于 90%,模型收敛效果好。
